I decided to write this article because the question about COUNT(*) Vs COUNT(1) keeps being asked, and I usually find myself explaining my answer again and again and/or looking for links to someone else’s articles that can help support my answer.
Here I discuss a couple of common misconceptions and share a short but irrefutable demonstration.
So, these are the question I will answer here:
What is the difference between COUNT(*) and COUNT(1)?
Short answer: None!
Is COUNT(1) more efficient or faster than COUNT(*)?
Short answer: No!
Is there a way to demonstrate or prove that they are the same thing?
Short answer: Yes!
What is the difference between COUNT(*) and COUNT(1)?
One of the most common answers I see for this question is that they might produce different results because COUNT(1) counts only rows in which the first column is not null.
Why is that answer incorrect?
Because COUNT receives an expression as parameter, not a column position. COUNT(1) doesn’t mean COUNT(<first column>). It means COUNT(1), with 1 being treated as a numeric literal.
The confusion comes most likely from the fact that you can use a column position in the ORDER BY clause, but using column positions is not allowed with the COUNT function.
Look at the syntax diagram for the ORDER BY CLAUSE:
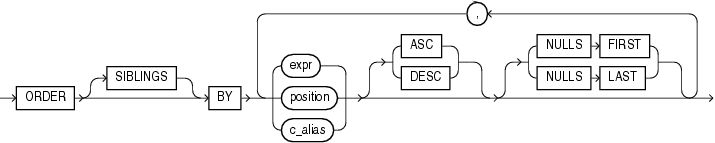
Order By clause syntax diagram.
As you can see, it explicitly says that you can provide a position instead of an expression or an alias, but if you look at the syntax of the COUNT function, it expects an expression:

Count function syntax diagram.
So, what is the consequence of 1 being treated as a numeric literal by the COUNT function?
Well, it is true that COUNT counts only rows in which the expression passed is not null, but since 1 is a literal, and a literal doesn’t change, it will always be 1, for each and every row, and will never be null, so the final result is that COUNT(1) counts all of the rows returned by the query, regardless of the existence of nulls in any of the columns.
If you have doubts, try this query:
SELECT COUNT(99999), COUNT('MONKEY'), COUNT(*) FROM DUAL;
If the parameter passed to COUNT was treated as a column position, then the first call to COUNT would produce an error, because there is only one column in the dual table.
And the second call to COUNT shows you that you can use any type of literal, and the result is the same, because, again, a literal will not change, and thus ‘MONKEY’ will never be null, so, COUNT(1), COUNT(99999) and COUNT(‘MONKEY’) are all equivalent to COUNT(*).
Is COUNT(1) more efficient or faster than COUNT(*)?
The most common argument in favor of COUNT(1) I have seen in this kind of discussion is that COUNT(*) needs to check the value of all columns in the row to determine if it needs to be counted, because COUNT doesn’t count nulls.
Why is that incorrect?
Because the official documentation about the COUNT function explicitly says this:
“If you specify the asterisk (*), then this function returns all rows, including duplicates and nulls.”
So, COUNT(*) always counts all rows, and thus, the database doesn’t need to check the column values, because it will always count all rows, regardless of their contents.
Is there a way to demonstrate or prove that they are the same thing?
I have seen some people use execution plans to demonstrate that COUNT(1) is equivalent to COUNT(*), but unfortunately, an execution plan comparison is not enough because even if they were different, and one of them actually did more work than the other one, the execution plans could still be equal, so that is not a convincing or irrefutable demonstration.
If you want irrefutable proof, here it is, and if you really want to find the truth, this should be enough to make you take the correct side of this debate, forever 🙂

The proof:
There is a part of the database software that is called “The Optimizer”, which is defined in the official documentation as “Built-in database software that determines the most efficient way to execute a SQL statement“.
One of the components of the optimizer is called “the transformer”, whose role is to determine whether it is advantageous to rewrite the original SQL statement into a semantically equivalent SQL statement that could be more efficient.
The optimizer does a lot of work under the hood, but we usually don’t notice it.
Would you like to see what the optimizer does when you write a query using COUNT(1)?
I’m going to show you how to generate an optimizer trace, also known as a 10053 trace, in which you will be able to see a log of the optimizer work. There are more methods to do it, but here is one:
You will have to use a database user to which the ALTER SESSION privilege has been granted.
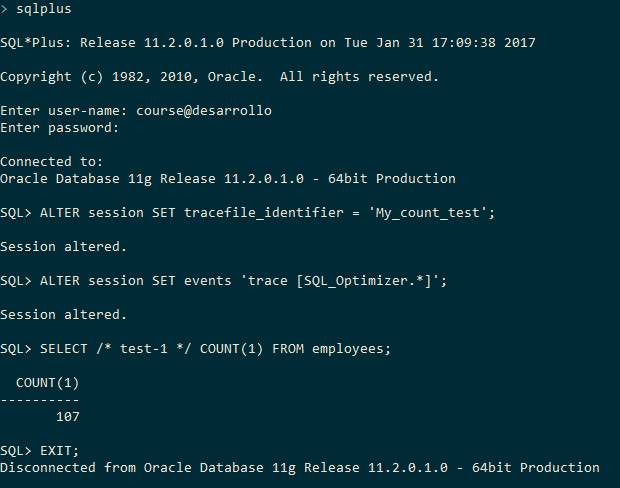
I’m doing this on a SQL*Plus session, but if you are using SQL Developer, you might need to manually disconnect the session instead of executing the EXIT command in the last step.
First, you need to do something to make your trace file easy to identify:
ALTER SESSION SET tracefile_identifier = 'My_count_test';
Then you have to enable the optimizer tracing:
ALTER SESSION SET events 'trace [SQL_Optimizer.*]';
Then you have to run the command you want to trace, which in this case is a SELECT statement that uses COUNT(1):
SELECT /* test-1 */ COUNT(1) FROM employees;
For the trace to be generated, a “hard parse” of the statement needs to occur, and in simplified words, it will occur if the exact same statement has not been executed before, so if you want to run and trace the same statement several times, make sure to add a comment that makes it different from the other times you have run the same statement. In this case, if I want to trace the same statement again, I would change the comment to ‘test-2’, for example.
Ok, now, you need to exit the session for the trace to be written to the file:
EXIT;
As I mentioned before, if you are using SQL Developer, you might need to manually disconnect the session, as just executing EXIT or DISCONNECT doesn’t appear to really end the session.
Here is how this looks like on my system:
And now, the exciting part! We are going to take a look at the contents of the trace we generated, but where is this file located?
It might vary from system to system, but you can fire this query to see the path where the trace files are located:
SELECT VALUE FROM V$DIAG_INFO WHERE NAME = 'Diag Trace';
Ok, here are the relevant portions of the 1850-lines trace file that was generated.
******************************************
—– Current SQL Statement for this session (sql_id=4nbgdngzf4024) —–
SELECT /* test-1 */ COUNT(1) FROM employees
*******************************************
Legend
The following abbreviations are used by optimizer trace.…
CNT – count(col) to count(*) transformation
…
As you can see, there is a “count(col) to count(*)” transformation, that is represented in the trace as CNT.
A little later in the trace, there is this:
CNT: Considering count(col) to count(*) on query block SEL$1 (#0)
*************************
Count(col) to Count(*) (CNT)
*************************
CNT: COUNT() to COUNT(*) done.
And a little later, there is this:
Final query after transformations:******* UNPARSED QUERY IS *******
SELECT COUNT(*) “COUNT(1)” FROM “COURSE”.”EMPLOYEES” “EMPLOYEES”
Do you see the role “COUNT(1)” plays in the final query?
I will put it here again, as an image:
![]()
“COUNT(1)” is just an alias! What Oracle actually runs is COUNT(*) but it returns COUNT(1) as the column title in the results, because that is what you asked for, but it actually runs COUNT(*)!
So, NO, COUNT(1) is not more efficient nor faster than COUNT(*), because COUNT(1) is actually never run. It is always transformed into COUNT(*), so you always do COUNT(*) even if you don’t want it.
I could even say that COUNT(1) is at least a little bit less efficient, because it requires the optimizer to do a transformation that would not be needed if COUNT(*) was used from the beginning.
Are we on the same side now?
Great!
Have something to say?
Great! Post your comments below.