This is the written version of a lesson from The Ultimate Oracle SQL Course, in which I show how to use the Oracle FIRST and LAST functions.
Like some other functions you probably know, these functions can be used either as aggregate functions or as analytic functions.
I will show you how to use them as aggregate functions first, and then, at the end, will show you an example of how to use them as analytic ones.
Why Did I Write About Them?
I love these functions for 2 reasons:
First: They can simplify the solution of some kind of problems, and can also solve them more efficiently. In some cases, they can be used as aggregate functions and still solve problems more efficiently than analytic functions, which is awesome.
And second: Many people, or maybe I should say, MOST people don’t know how to use them, so if you learn them well and get used to them, you could be seen as a very knowledgeable developer, and I really like that, because I want you to stand out!
How Do The Oracle FIRST and LAST Functions Work?
To explain how they work, I’m going to solve a very simple fictitious problem.
This is the data in a simple employee table I will use for the explanation:
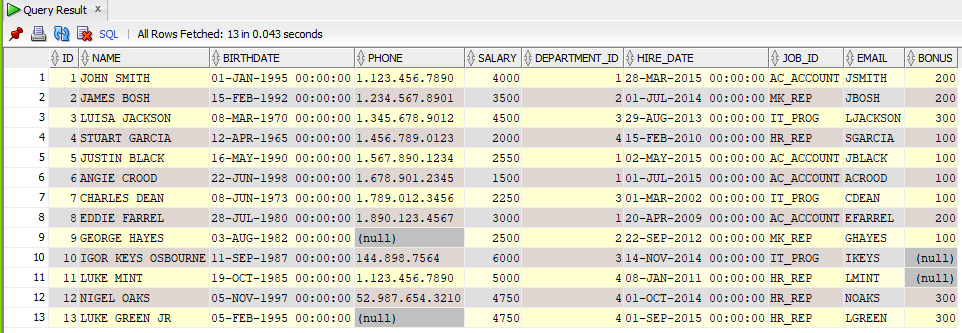
Now let’s suppose that I have to return the hire date of the employee with the greatest id.
So, I have to condition the query to return the row for the employee with the greatest id, and to know which one is the greatest id, I need a subquery, right?
So, the query would look something like this:
SELECT hire_date FROM employee WHERE id = ( SELECT MAX(id) FROM employee );
As you see, I’m querying the employee table twice.
Now, instead of using a subquery, I can do something like this:
SELECT MAX(hire_date) KEEP ( DENSE_RANK LAST ORDER BY id ) FROM employee;
Which produces the same results, but without needing to query the table twice.
So, how does it work?
In summary, this will apply the MAX function to the set of rows defined by what we have in lines 4 and 5, inside the parentheses after the KEEP keyword, which is where we are actually using the LAST function.
That part of the code will internally apply a dense rank to the rows ordered by id and will keep the rows with the LAST or greatest rank.
In this case, since we are ordering by id, which is the primary key of this table, we know that there will be only one row with the greatest rank, but if we were ordering by salary, for example, and there were several employees with the highest salary, this would keep all of those rows, because since all of them earn the highest salary, all of them would have the same dense rank.
So, after we define the rows we want to keep, the aggregate function, which in this case is MAX of hire date, is applied only to those rows.
I have to say that I don’t really know why Oracle calls FIRST and LAST “functions”.
As you just saw, LAST is just that word at the end of line 4, inside all that construct. You cannot pass any parameter to it, and it does always the same thing, which is, defining that the rows that are to be kept are the ones that rank LAST.
It doesn’t return anything by itself. It is just a part of the definition of the rows to which we will apply an actual function, which in this case is MAX.
Also, the syntax to use them is very different from how we usually call other aggregate or analytic functions, and that is probably one of the reasons why not many people know or remember how to use them.
I think it would make more sense to call KEEP a clause, and call DENSE_RANK FIRST or LAST a subclause of it.
But anyway, we have to call them functions, because that is how Oracle calls them in the official docs.
As I mentioned before, in this case, this is keeping only one row, so I could have used MIN instead of MAX here, and the results would be the same because this function is being applied only to that one row, but in cases where more than one row is kept, then using MAX or MIN could produce different results.
And in case you are wondering: No, you cannot use RANK or any other of the ranking functions there. The only valid ranking function there is DENSE_RANK.
Most Common Use Case
One of the most common use cases for Oracle FIRST and LAST is when you have a grouped query to get the max or min of some column, and you need to get some additional data from that row which happens to be the maximum or minimum you are interested in.
For example, if I wanted to know what the birth date of the oldest employee per department is, I could get it easily this way:
SELECT department_id, MIN(birthdate) FROM employee GROUP BY department_id;
But, what should I do if now I want to know the name of the employee who is the oldest as well?
I could use a subquery, as in the previous example, or I could use an analytic function, as in the next example we are going to look at, but the easiest and most efficient way to do it would be like this:
SELECT department_id, MIN(birthdate), MAX(name) KEEP ( DENSE_RANK FIRST ORDER BY birthdate ) AS name FROM employee GROUP BY department_id;
In this case, the Oracle FIRST function is keeping the row(s) in which the birthdate is the minimum in the department (because rows are being dense_rank’ed based on the birthdate), so, it is keeping the same row from which the MIN function got its result, but it allows me to return the value of some other column, in this case, the name.
As you see, I had to use the MAX function to get the name, because an aggregate function is required there, but in cases where only one row is kept, the aggregate function doesn’t do anything, and it could be either MIN or MAX and the results would be the same.
Keep in mind though, that if more than one row is kept, then you would get only the minimum or maximum of all of the rows kept (or the count or average for that matter, depending on the aggregate function we use), and we can only be sure that only one row will be kept if there is a unique constraint or index on the column by which we order the rows to get the dense rank.

A More Complex Example
I’m going to show you another example, which is a little more complex.
Let’s suppose that I want to know the number of employees who earn the smallest bonus in each department. So, for example, if in the ACCOUNTING department the smallest bonus is 100, I want to know how many employees of the ACCOUNTING department earn that bonus.
There are several ways to solve a problem like this one.
One option would be getting the minimum bonus for each department in a subquery, and then in the main query return only the employees who earn that min bonus.
It would look something like this:
SELECT department_id, COUNT(*) AS employees FROM employee WHERE (department_id, bonus ) IN ( SELECT department_id, MIN(bonus) FROM employee GROUP BY department_id ) GROUP BY department_id ORDER BY department_id;
The subquery gives me the minimum bonus of each department, and then in the main query, I return only the rows that have the same department id and bonus as one of the minimums returned by the subquery.
Now, here I’m querying the employee table twice, but I could use an analytic function to avoid doing that.
So, another way to solve the problem would be like this:
SELECT department_id, COUNT(*) AS employees FROM ( SELECT department_id, bonus, DENSE_RANK() OVER(PARTITION BY department_id ORDER BY bonus) AS rn FROM employee ) WHERE rn = 1 GROUP BY department_id ORDER BY department_id;
In the in-line view (starts at line 3) I’m ranking the rows based on the bonus, so the rank number one will be assigned to the employees with the smallest bonus in each department.
And in the main query, I have a condition to only include rows where the rank is equal to 1, which will give me all of the employees who earn the smallest bonus in each department, and then I group by department id to get the count of rows for each department.
This is a variant of a top-1 query, as you may have noticed.
I’m only querying the table once this time, so this solution would tend to be more efficient.
But now, take a look at this solution:
SELECT department_id, COUNT(*) KEEP ( DENSE_RANK FIRST ORDER BY bonus ) AS employees FROM employee GROUP BY department_id ORDER BY department_id;
As you see, this one doesn’t even need a subquery, and it produces the exact same results. And it is not only simpler but would also tend to be even more efficient.
Here it applies a dense rank ordered by bonus and keeps only the rows with the smallest or FIRST rank, and then it applies the COUNT function to only those rows, all of this in the same operation!
So, is this awesome or not?
I still need to group by department_id because I want the count per department, but this query is definitely simpler than the other 2 solutions, and in many cases would also be more efficient than both of them.
Now, if instead of wanting the minimum bonus I were interested in the maximum, I would just have to use the LAST function, instead of FIRST.
So, these functions work exactly the same, but one keeps the rows that rank FIRST and the other one keeps the rows that rank LAST.
And I could use a descending order in line 5, in which case the rank number 1 would be assigned to the employee with the highest bonus. So, if you think about it, using LAST with a descending order produces the same results as using FIRST with an ascending order.
Using Oracle FIRST and LAST as Analytics
Now, if you want to use them as analytic functions, you only have to add an analytic clause, which as you know, starts with the OVER keyword.
The only restrictions they have as analytic functions, is that they cannot include an order by clause, because the keep clause already includes one, and they cannot include a windowing clause either, so, the only analytic subclause you can include is the partition clause.
So, if we want to convert the function call in our previous example to an analytic one, I just have to add the analytic clause and then remove the GROUP BY clause, because I don’t have aggregates now, and it would like like this:
SELECT department_id, COUNT(*) KEEP ( DENSE_RANK FIRST ORDER BY bonus ) OVER ( PARTITION BY department_id ) AS employees FROM employee ORDER BY department_id;
As expected with analytic functions, the results for each department are the same as with the aggregate version, but now I get all of the rows, not only one per department.
And I could easily add other columns now if I wanted to, for example, the name of the employee or any other data, because I no longer have a group by clause.
So, these functions are very powerful and can be very useful, especially when used as aggregates, in my opinion. When I need the analytic version, I usually tend to prefer FIRST_VALUE and LAST_VALUE, which I will cover in another article.
Can you think of a situation where you could use them?
Great, go play with them ASAP!
P.s. If you want to check the official documentation of the Oracle FIRST and LAST functions, here it is: Oracle FIRST Function
See you soon!

Subscribe to be informed about new posts, tips and more awesome things.