I’ve worked with Oracle databases for many years, and during this time I have seen code written by lots of different people. One thing I have noticed is that with few exceptions, people who started working with Oracle many years ago tend to write an inner join in some way and people newer to the database do it in a different way, so there are 2 predominant syntaxes used. However, there are at least 2 more ways to code an inner join which leaves us with 4 different methods to achieve the same thing (not all of them applicable in all cases). Let’s take a look at them.
The Old Inner Join Syntax: Filtered cartesian product
This is the one most “old” Oracle developers tend to use, and the reason for that is that it was the only possible way to do it before version 9i.
In this method, we create a cartesian product which is filtered by adding the join condition in the WHERE clause. For example, if we have these two tables: department and employee, and we want an inner join of them, we would write something like this:
SELECT e.employee_id, d.department_name FROM employee e, department d WHERE e.department_id = d.department_id AND e.salary > 1000;
So, we have to put the join condition and any other filter we need all in the WHERE clause. If we fail to provide an appropriate join condition we end up with a probably unwanted cartesian product.
The New Standard Syntax: The JOIN clause
This is the syntax most not-so-old developers tend to use, and is the one that conforms to the ANSI standard. I started using it about 3 years ago and any time I need to make changes to old code I use the opportunity to change joins to this new syntax.
The previous example would look like this with this method:
SELECT e.employee_id, d.department_name FROM employee e JOIN department d ON e.department_id = d.department_id WHERE e.salary > 1000;
The JOIN clause is actually part of the FROM clause, so, as you can see, now we have only one condition in the WHERE clause, and we have the join condition as part of the JOIN clause, which for me makes things more understandable. The JOIN keyword is used for different kinds of joins, but the INNER join is the default one, so for inner joins, we don’t need to specify the type.
So, how does it work?
We use the JOIN clause to join exactly 2 sources (no more, no less), in this case, the employee and department tables, and then we need to provide the join condition(s) by means of the ON keyword. In this example we used an equality condition, but you can have joins using <, > or something else, and we can have more than one join condition, in which case we can use ANDs and ORs as one would normally do in a WHERE clause.
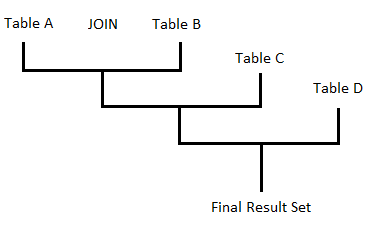
As a result of joining those 2 sources, Oracle creates a join table, which will become a single source that can be used to join some other table or view, and it continues in that cycle until you have joined all of the sources you wanted to join.
This image shows how it works:
Let’s see an example with more than one join condition and more than 2 tables:
SELECT e.employee_id, dep.department_name, div.division_name FROM employee e JOIN department dep ON e.department_id = dep.department_id JOIN division div ON dep.division_id = div.division_id AND dep.country_id = div.country_id WHERE e.salary > 1000;
First ANSI variant: The USING clause
The ANSI standard for joins includes a way to write less code when you are writing joins that comply with certain conditions. If the join you are writing is an equi join (I mean, the condition is an equality one) and the columns involved in the join conditions are named the same in both sources (tables, views), then you can use the USING clause as a ‘shorthand’.
The syntax is very simple:
USING (column1 [, column2, ..., column n])
And here is how the query from the previous example would be written with this abbreviated method:
SELECT e.employee_id, dep.department_name, div.division_name FROM employee e JOIN department dep USING (department_id) JOIN division div USING (division_id, country_id) WHERE e.salary > 1000;
As you can see, the join conditions are shorter using this method.
There’s one little thing you need to know if you plan to use this syntax: If a column included in the USING clause is part of the SELECT list, you can’t qualify it with the table name or its alias, so if you select one of those columns, just include the column name. There won’t be ambiguity because Oracle internally includes it only once, as part of the resulting join table (not as a member of any of the original ones).

Second ANSI variant: The NATURAL join
The ANSI standard provides another option to write less code if we want to join our tables using all of the columns that have the same name in both sources.
In the case of our previous example, we could use the NATURAL join to get the same results only if the only common column between employee and department were department_id, and the only common columns between department and division were division_id and country_id. If there were other columns with the same name but unmatched data, we would get an empty result set.
So, assuming the necessary condition is met, this is how our example query would look like by using natural joins:
SELECT e.employee_id, dep.department_name, div.division_name FROM employee e NATURAL JOIN department dep NATURAL JOIN division div WHERE e.salary > 1000;
In this case, we performed a NATURAL INNER join, but it is possible to do NATURAL OUTER joins too. You would just have to specify the type of join you want. In this case, we didn’t need to do it because inner is the default join type.
Warning: Be very careful if you decide to use natural joins inside applications or scripts, since it can cause you problems in the future if the joined tables are subject to modifications. Your current joins would be broken if the name of one of the joined columns changes, and new joins can be added unintentionally if you rename or add new columns.
Okay, there you have it: 4 different ways to do inner joins. Which one do you like or use more?

Subscribe to be informed about new posts, tips and more awesome things.